选择排序
定义:首先,找到数组中最小的那个元素,其次,将它和数组的第一个元素交换位置(如果第一个元素就是最小元素那么它就和自己交换)。再次,在剩下的元素中找到最小的元素,将它与数组的第二个元素交换位置。如此往复,直到将整个数组排序。
特点:
- 运行时间与输入无关
- 数据移动时最少的


伪代码:
1 | class Solution { |
该算法将第i小的元素放到a[i] 之中。数组的第i 个位置的左边是i个最小的元素且它们不会再被访问。
插入排序($O(n^2)$)
定义:将一个待排序的序列插入到一个前面已排好序的子序列当中。
为了给要插入的元素腾出空间,我们需要将其余所有元素在插入之前都向右移动一位。当前索引左边的所有元素都是有序的,但它们的最终位置还不确定,为了给更小的元素腾出空间,它们可能会被移动。但是当索引到达数组的右端时,数组排序就完成了。
特点:
- 插入排序所需的时间取决于输入中元素的初始顺序

步骤:

- 初始L[1]是一个已经排好序的子序列
- 对于元素
L[i](L[2]~L[])插入到前面已经排好序的子序列当中
- 查找出
L[i]在L[1,...,i-1]中的插入位置k - 将
L[k,...,i-1]中的所有元素后移一个位置 - 将
L[i]复制到l[k]
代码1:
1 | class Solution { |
代码2:
1 | void InsertSort(ElemType A[],int n){ |
对于1 到N-1 之间的每一个i,将a[i] 与a[0] 到a[i-1] 中比它小的所有元素依次有序地交换。在索引i 由左向右变化的过程中,它左侧的元素总是有序的,所以当i 到达数组的右端时排序就完成了。
要大幅提高插入排序的速度并不难,只需要在内循环中将较大的元素都向右移动而不总是交换两个元素(这样访问数组的次数就能减半)
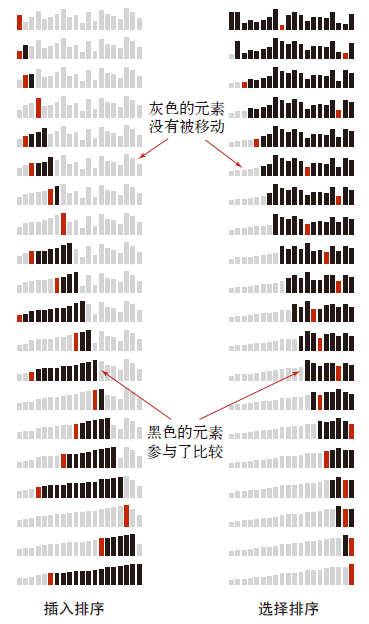
性质:
- 对于长度为
N的数组,选择排序需要大约$N^2/2$次比较和$N$ 次交换。 - 对于随机排列的长度为
N且主键不重复的数组,平均情况下插入排序需要~ $N^2/4$ 次比较以及~ $N^2/4$ 次交换。最坏情况下需要~ $N^2/2$ 次比较和~ $N^2/2$ 次交换,最好情况下需要$N-1$次比较和$0$ 次交换。 - 插入排序需要的交换操作和数组中倒置的数量相同,需要的比较次数大于等于倒置的数量,小于等于倒置的数量加上数组的大小再减一。
- 对于随机排序的无重复主键的数组,插入排序和选择排序的运行时间是平方级别的,两者之比应该是一个较小的常数。
折半插入排序
1 | void BInsertSort(ElemType A[],int n){ |
希尔排序
定义:基于插入排序的快速排序算法
希尔排序为了加快速度简单地改进了插入排序,交换不相邻的元素以对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。
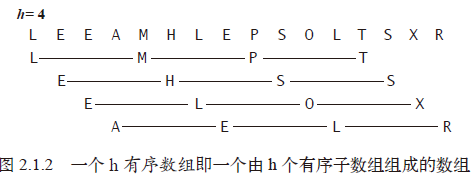
使数组中任意间隔为
h的元素都是有序的。这样的数组被称为h有序数组。实现希尔排序的一种方法是对于每个h,用插入排序将h个子数组独立地排序。但因为子数组是相互独立的,一个更简单的方法是在
h-子数组中将每个元素交换到比它大的元素之前去(将比它大的元素向右移动一格)。只需要在插入排序的代码中将移动元素的距离由1 改为h即可。这样,希尔排序的实现就转化为了一个类似于插入排序但使用不同增量的过程。
伪代码:
1 | class Solution { |

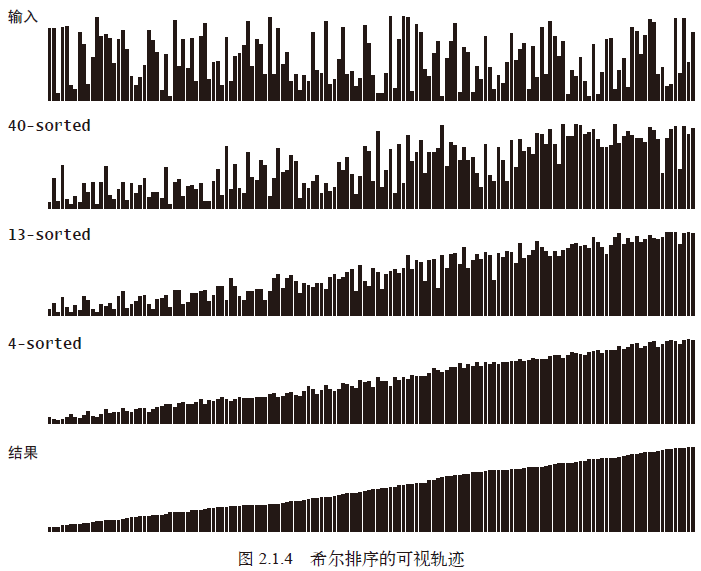
性质:
- 算法的性能不仅取决于
h,还取决于h之间的数学性质,比如它们的公因子等。 - 希尔排序比插入排序和选择排序要快得多,并且数组越大,优势越大。
- 使用递增序列1, 4, 13, 40, 121, 364…的希尔排序所需的比较次数不会超出N 的若干倍乘以递增序列的长度。
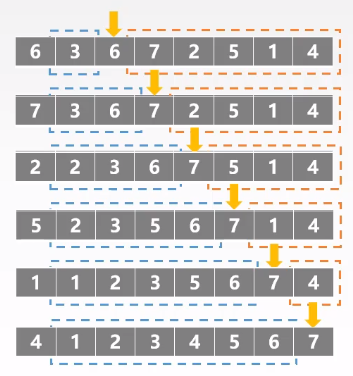
归并排序
定义:将两个有序的数组归并成一个更大的有序数组。要将一个数组排序,可以先(递归地)将它分成两半分别排序,然后将结果归并起来。
能够保证将任意长度为
N的数组排序所需时间和$NlogN$成正比;它的主要缺点则是它所需的额外空间和N成正比。

原地归并
定义:将两个不同的有序数组归并到第三个数组中。创建一个适当大小的数组然后将两个输入数组中的元素一个个从小到大放入这个数组中。
思路:归并排序利用了分治的思想来对序列进行排序。对一个长为 $n$ 的待排序的序列,我们将其分解成两个长度为$ \frac{n}{2} $ 的子序列。 每次先递归调用函数使两个子序列有序,然后我们再线性合并两个有序的子序列使整个序列有序。
算法:
定义 mergeSort(nums, l, r) 函数表示对 nums 数组里[l,r]的部分进行排序,整个函数流程如下:
递归调用函数
mergeSort(nums, l, mid)对nums数组里[l,mid]部分进行排序;递归调用函数
mergeSort(nums, mid + 1, r)对nums数组里[mid+1,r]部分进行排序;此时
nums数组里[l,mid]和[mid+1,r]两个区间已经有序,我们对两个有序区间线性归并即可使nums数组里[l,r]部分有序。线性归并的过程并不难理解,由于两个区间均有序,所以我们维护两个指针
i和j表示当前考虑到[l,mid]里的第i个位置和[mid+1,r]里的第j个位置。如果
nums[i] < nums[j], 那么我们就将nums[i]放进临时数组tmp中并让i+1,即指针后移。否则我们将nums[j]放入临时数组tmp中并让j+1。 如果有一个指针已经移到了区间的末尾,那么就把另一个区间里的数按顺序加入tmp数组中即可。这样能保证我们每次都是让两个区间中较小的数加入临时数组里,那么整个归并过程结束后
[l,r]即为有序的。函数递归调用的入口为
mergeSort(nums, 0, nums.length - 1),递归结束当且仅当l >= r。
归并结果:

伪代码:
1 | public static void merge(Comparable[] a, int lo, int mid, int hi){ |
例子:
1 | class Solution { |
自顶向下
思路:如果它能将两个子数组排序,它就能够通过归并两个子数组来将整个数组排序。
归并结果:

伪代码:
1 | public class Merge{ |
排序轨迹:

自底向上
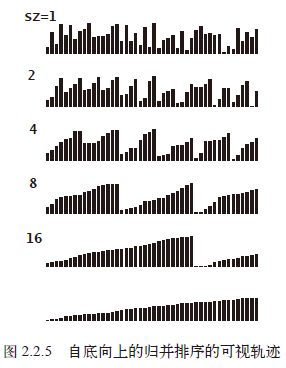
思路:分治法,实现归并排序的另一种方法是先归并那些微型数组,然后再成对归并得到的子数组,如此这般,直到我们将整个数组归并在一起。
首先我们进行的是两两归并(把每个元素想象成一个大小为1 的数组),然后是四四归并(将两个大小为2 的数组归并成一个有4个元素的数组),然后是八八的归并,一直下去。
归并结果:

伪代码:
1 | public class MergeBU{ |
排序轨迹:
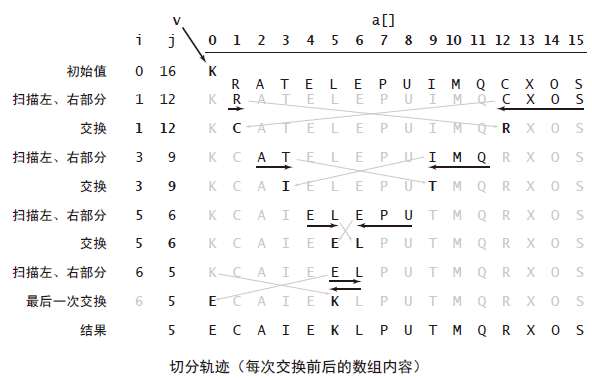
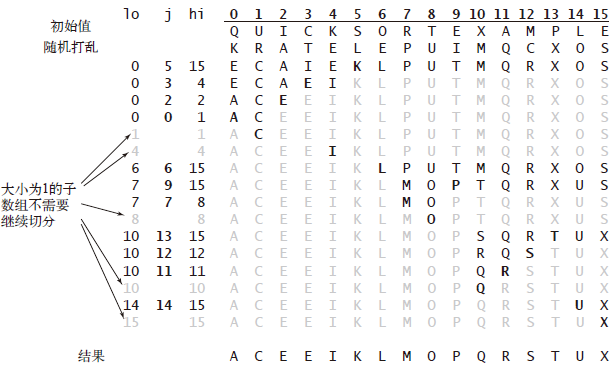
快速排序
定义:它将一个数组分成两个子数组,将两部分独立地排序。
思路:分治法,与归并排序互补:归并排序将数组分成两个子数组分别排序,并将有序的子数组归并以将整个数组排序(递归发生在处理整个数组之前);而快速排序将数组排序的方式则是当两个子数组都有序时整个数组也就自然有序了(递归发生在处理整个数组之后)。
示意图:
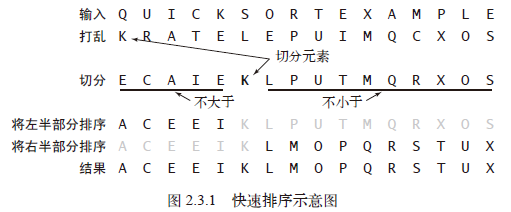
排序结果:
伪代码:
1 | void quickSort(int left, int right, vector<int>& arr) |