数字序列中某一位的数
数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从0开始计数)是5,第13位是1,第19位是4,等等。请写一个函数求任意位对应的数字。
样例
1 | 输入:13 |
思路
递推
- 将$101112…$中的每一位称为数位,记为$n$;
- 将$10$、$11$、$12$、、、成为数字,记为$num$;
- 数字$10$是一个两位数,称此数的位数为$2$,记为$digit$;
- 每$digit$位数的起始数字($10$、$11$、$12$、、、),记为$start$。
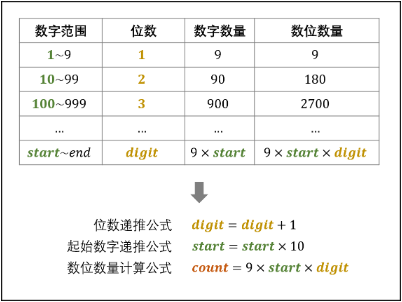
根据以上凡汐,可将其分解为三步:
确定$n$所在数字的位数,记为$digit$;
- 循环执行$n$减去 一位数、两位数、… 的数位数量$count$,直至$n \leq count$时跳出。
- 由于$n$已经减去了一位数、两位数、…、$(digit−1)$位数的数位数量$count$,因而此时的$n$是从起始数字$start$开始计数的。
- 所求数位 ① 在某个$digit$位数中; ② 为从数字$start$开始的第$n$个数位。
1
2
3
4
5
6digit = 1, start = 1, count = 9;
while(n > count):
n -= count
start *= 10 # 1, 10, 100, ...
digit += 1 # 1, 2, 3, ...
count = 9 * start * digit # 9, 180, 2700, ...确定$n$所在数字,记为$num$;
- 所求数位的数字在从$start$开始的第$[(n - 1) / digit]$个数字中($start$为第0个数字)
- $num = start + (n - 1) // digit $
确定$n$是$num$中的哪一位,并返回。
所求数位为数字$num$的第$(n - 1) \% digit$位(数字的首个数位为第0位)。
1
2s = str(num) # 转化为 string
res = int(s[(n - 1) % digit]) # 获得 num 的 第 (n - 1) % digit 个数位,并转化为 int
算法时间复杂度
时间复杂度$O(\log n)$: 所求数位$nn$对应数字$num$的位数$digit$最大为$O(\log n)$;第一步最多循环$O(logn)$次;第三步中将$num$转化为字符串使用$O(logn)$时间;因此总体为$O(logn)$。
C++代码
1 | class Solution { |
把数组排成最小的数
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组[3, 32, 321],则打印出这3个数字能排成的最小数字321323。
样例
1 | 输入:[3, 32, 321] |
注意:输出数字的格式为字符串。
思路
定义新的排序规则
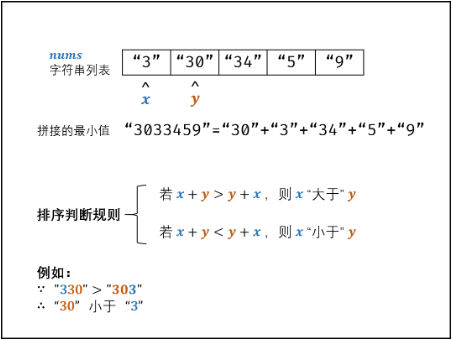
- 排序判断规则:设$nums$任意两数字的字符串格式为$x$和$y$,则:
- 若拼接字符串$x+y>y+x$,则$x>y$;
- 反之,若$x+y<y+x$,则$x<y$。
- 根据以上规则,套用任何排序方法对$nums$进行排序。
算法时间复杂度
时间复杂度$O(N \log N)$:$N$为最终返回值的字符数量(列表的长度$\leq N$);使用快排或内置函数的平均时间复杂度为$O(NlogN)$,最差为$O(N^2)$。
C++代码
1 | class Solution { |
把数字翻译成字符串
给定一个数字,我们按照如下规则把它翻译为字符串:0翻译成”a”,1翻译成”b”,……,11翻译成”l”,……,25翻译成”z”。一个数字可能有多个翻译。例如12258有5种不同的翻译,它们分别是”bccfi”、”bwfi”、”bczi”、”mcfi”和”mzi”。请编程实现一个函数用来计算一个数字有多少种不同的翻译方法。
样例
1 | 输入:"12258" |
思路
动态规划

状态表示: 设动态规划列表$dp$,$dp[i]$代表以$x_i$为结尾的数字的翻译方案数量。
转移方程:若$x_i$和$x_{i-1}$组成的两位数字可以被翻译,则$dp[i] = dp[i - 1] + dp[i - 2]$;否则$dp[i] = dp[i - 1]$。
- 边界条件:初始状态: $dp[0]=dp[1]=1$,即 “无数字” 和 “第1位数字” 的翻译方法数量均为1;$dp[n]$ ,即此数字的翻译方案数量。
算法时间复杂度
C++代码
1 | /* |
礼物的最大价值
在一个m×n的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格直到到达棋盘的右下角。给定一个棋盘及其上面的礼物,请计算你最多能拿到多少价值的礼物?
注意:m,n>0m,n>0
样例
1 | 输入: |
思路
动态规划
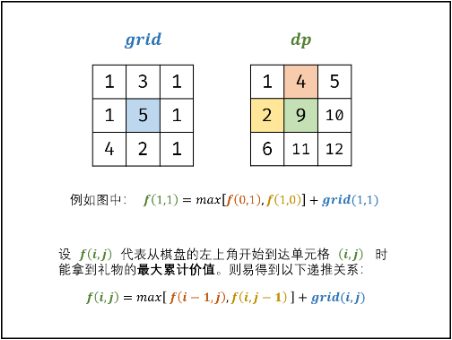
状态表示:$f[i,j]$——从左上角走到当前$[i,j]$处最大礼物累积
转移方程:$f[i,j]=max[f[i-1,j],f[i,j-1]]+grid[i,j]$
边界条件:
初始状态:$f[0,0]=grid[0,0]$
返回值:$f[m-1][n-1]$,$m,n$分别为矩阵的行高和列宽,即右下角。
算法时间复杂度
时间复杂度$O(MN)$: $M, N$分别为矩阵行高、列宽;动态规划需遍历整个$grid$矩阵,使用$O(MN)$时间。
C++代码
1 | class Solution { |
最长不含重复字符的子字符串
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。假设字符串中只包含从’a’到’z’的字符。
样例
1 | 输入:"abcabc" |
思路
双指针
算法时间复杂度
C++代码
1 | class Solution { |
丑数
我们把只包含质因子2、3和5的数称作丑数(Ugly Number)。例如6、8都是丑数,但14不是,因为它包含质因子7。求第n个丑数的值。
样例
1 | 输入:5 |
注意:习惯上我们把1当做第一个丑数。
思路
三路归并排序
1 | nums2 = {1*2, 2*2, 3*2, 4*2, 5*2, 6*2, 8*2...} |
包含2的除以2,包含3的除以3,包含5的除以5——判重合并(并集)之后可以得到丑数序列!!
判重:
算法时间复杂度
C++代码
1 | class Solution { |
字符串中第一个只出现一次的字符
在字符串中找出第一个只出现一次的字符。如输入"abaccdeff",则输出b。如果字符串中不存在只出现一次的字符,返回#字符。
样例:
1 | 输入:"abaccdeff" |
思路
模拟,哈希表
算法时间复杂度
C++代码
1 | class Solution { |
字符流中第一个只出现一次的字符
请实现一个函数用来找出字符流中第一个只出现一次的字符。例如,当从字符流中只读出前两个字符”go”时,第一个只出现一次的字符是’g’。当从该字符流中读出前六个字符”google”时,第一个只出现一次的字符是’l’。如果当前字符流没有存在出现一次的字符,返回#字符。
样例
1 | 输入:"google" |
思路
双指针——队列,动态的过程
每次出现重复的字母,将其全部删掉
维护一个哈希表,记录从前往后字符出现的次数。
算法时间复杂度
C++代码
1 | class Solution |
数组的逆序对
在数组中的两个数字如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
样例
1 | 输入:[1,2,3,4,5,6,0] |
思路
归并排序
「归并排序」是分治思想的典型应用,它包含这样三个步骤:
算法时间复杂度
C++代码
1 | // 暴力—— 50% |
两个链表的第一个公共节点
输入两个链表,找出它们的第一个公共结点。当不存在公共节点时,返回空节点。
样例
1 | 给出两个链表如下所示: |
思路
双指针
我们使用两个指针node1,node2分别指向两个链表headA,headB的头结点,然后同时分别逐结点遍历,当node1到达链表headA的末尾时,重新定位到链表headB的头结点;当node2到达链表headB的末尾时,重新定位到链表headA的头结点。这样,当它们相遇时,所指向的结点就是第一个公共结点。
算法时间复杂度
C++代码
1 | class Solution { |
数字在排序数组中出现的次数
统计一个数字在排序数组中出现的次数。例如输入排序数组[1, 2, 3, 3, 3, 3, 4, 5]和数字3,由于3在这个数组中出现了4次,因此输出4。
样例
1 | 输入:[1, 2, 3, 3, 3, 3, 4, 5] , 3 |
思路
二分法
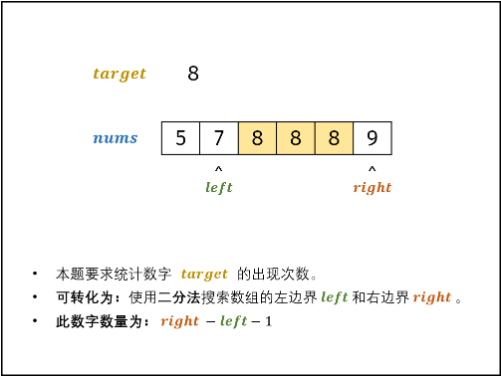
排序数组$nums$中的所有数字$target$形成一个窗口,记窗口的 左 / 右边界索引分别为$left$和$right$,分别对应窗口左边 / 右边的首个元素。
- 初始化:左边界$i=1$,右边界$r=nums.size() - 1$
- 循环二分:当闭区间$[i,j]$无元素就跳出来
- 计算中点$mid=(i+j)/2$
- 若$nums[mid]<target$,则$target$在闭区间$[mid+1,j]$中,执行$l=mid+1$;
- 若$nums[mid] > target$,则$target$在闭区间$[i,mid−1]$中,因此执行$j = mid - 1$;
- 若$nums[m] = target$,则右边界$right$在闭区间$[mid+1,j]$中;左边界$left$在闭区间$[i,mid-1]$中。因此分为以下两种情况:
- 若查找右边界$right$,则执行$i = mid + 1$;(跳出时$i$指向右边界)
- 若查找左边界$left$,则执行$j = mid - 1$;(跳出时$j$指向左边界)
- 返回值: 应用两次二分,分别查找$right$和$left$,最终返回$right - left - 1$即可。
算法时间复杂度
C++代码
1 | class Solution { |

